Badger源码导读(二)
源码分析入口基准案例
先从Badger的基本使用入手
func main() {
// 打开db
db, _ := badger.Open(badger.DefaultOptions("tmp/badger"))
defer db.Close()
// 读写事务
err := db.Update(func(txn *badger.Txn) error {
txn.Set([]byte("answer"), []byte("42"))
txn.Get([]byte("answer"))
return nil
})
// 只读事务
err = db.View(func(txn *badger.Txn) error {
txn.Get([]byte("answer_v1"))
return nil
})
// 遍历keys
err = db.View(func(txn *badger.Txn) error {
opts := badger.DefaultIteratorOptions
opts.PrefetchSize = 10
it := txn.NewIterator(opts)
defer it.Close()
for it.Rewind(); it.Valid(); it.Next() {
item := it.Item()
k := item.Key()
err := item.Value(func(val []byte) error {
fmt.Printf("key=%s, value=%s\n", k, val)
return nil
})
if err != nil {
return err
}
}
return nil
})
err = db.RunValueLogGC(0.7)
_ = err
}读写事务
在第一章db初始化的时候,我们发现参数opt里面有一个 orcale 实例
在事务的实现中oracle实例发挥着重要的作用
Oracle的实例,一个KV引擎并发事务的管理器,负责分配事务的版本号,用来实现MVCC功能oracle实例
func newOracle(opt Options) *oracle {
orc := &oracle{
isManaged: opt.managedTxns,
// 当前事务是否支持冲突检测
detectConflicts: opt.DetectConflicts,
// We're not initializing nextTxnTs and readOnlyTs. It would be done after replay in Open.
//
// WaterMarks must be 64-bit aligned for atomic package, hence we must use pointers here.
// See https://golang.org/pkg/sync/atomic/#pkg-note-BUG.
// 水位,用来进行并发控制
readMark: &y.WaterMark{Name: "badger.PendingReads"},
txnMark: &y.WaterMark{Name: "badger.TxnTimestamp"},
closer: z.NewCloser(2),
}
orc.readMark.Init(orc.closer)
orc.txnMark.Init(orc.closer)
return orc
}WaterMark.Init()
// Init initializes a WaterMark struct. MUST be called before using it.
func (w *WaterMark) Init(closer *z.Closer) {
// 固定100大小的缓冲mark channel
w.markCh = make(chan mark, 100)
go w.process(closer)
}mark 结构体
type mark struct {
// Either this is an (index, waiter) pair or (index, done) or (indices, done).
// 索引
index uint64
// 传递空结构体信息的channel
waiter chan struct{}
indices []uint64
// 是否完成的标志
done bool // Set to true if the index is done.
}核心方法-Update(func(*badger.Txn))
db.Update(func(*badger.Txn))
func (db *DB) Update(fn func(txn *Txn) error) error {
// 判断状态是否关闭
if db.IsClosed() {
return ErrDBClosed
}
// 事务启动和提交时间戳由最终用户管理。这只对构建在Badger之上的数据库有用(比如Dgraph)
if db.opt.managedTxns {
panic("Update can only be used with managedDB=false.")
}
txn := db.NewTransaction(true)
defer txn.Discard()
// 回调的闭包
if err := fn(txn); err != nil {
return err
}
return txn.Commit()
}newTransaction(bool)
func (db *DB) NewTransaction(update bool) *Txn {
return db.newTransaction(update, false)
}
func (db *DB) newTransaction(update, isManaged bool) *Txn {
// 设置是否只读事务,badger对读写并发的设计不同
// 只读事务比读写事务性能要更好(少做一些事情,不需要考虑并发控制如读写冲突等)
if db.opt.ReadOnly && update {
// DB is read-only, force read-only transaction.
update = false
}
// 创建事务实例
txn := &Txn{
// 只读标记
update: update,
// 反引用db
db: db,
count: 1, // One extra entry for BitFin.
size: int64(len(txnKey) + 10), // Some buffer for the extra entry.
}
// 标记读写事务
if update {
// 如果检测冲突
if db.opt.DetectConflicts {
// 记录写入事务的set,检测事务冲突
// 如读取一个已经修改了的事务就要进行检测
txn.conflictKeys = make(map[uint64]struct{})
}
// 记录当前的读写事务在事务上做了多少次set操作,所有插入都会进行记录
txn.pendingWrites = make(map[string]*Entry)
}
// 给事务分配一个读时间戳
if !isManaged {
// oracle进行事务版本号的分发
txn.readTs = db.orc.readTs()
}
return txn
}orcale.readTs()
func (o *oracle) readTs() uint64 {
if o.isManaged {
panic("ReadTs should not be retrieved for managed DB")
}
var readTs uint64
// 加锁
o.Lock()
// 获取全局事务号(后面在commit的时候就直到为什么是-1了)
readTs = o.nextTxnTs - 1
// 标记当前读事务时间戳,事务已经进入读取阶段
o.readMark.Begin(readTs)
o.Unlock()
// Wait for all txns which have no conflicts, have been assigned a commit
// timestamp and are going through the write to value log and LSM tree
// process. Not waiting here could mean that some txns which have been
// committed would not be read.
// 此时事务版本号已经分配好,而且也已经通知了事务的水位标记线,事务已经开始了
y.Check(o.txnMark.WaitForMark(context.Background(), readTs))
return readTs
}WaterMark.Begin() 方法
// Begin sets the last index to the given value.
func (w *WaterMark) Begin(index uint64) {
// 更改index
atomic.StoreUint64(&w.lastIndex, index)
// 写入之前创建的缓冲区为100的缓冲mark channel(消费方后面详解)
w.markCh <- mark{index: index, done: false}
}WaterMark.WaitForMark(ctx, index) 方法
传入读时间戳
// WaitForMark waits until the given index is marked as done.
// 等待比当前小的时间戳提交
func (w *WaterMark) WaitForMark(ctx context.Context, index uint64) error {
// w.DoneUntil() => 已提交事务的最大版本号
// 用读事务时间戳和已提交事务最大版本号进行比较
if w.DoneUntil() >= index {
return nil
}
waitCh := make(chan struct{})
// 如果发现有比当前事务号更小的,会等待小的读取事务全部提交完成之后,会回调waiter进行close
// 具体mark的处理过程见下文
w.markCh <- mark{index: index, waiter: waitCh}
select {
case <-ctx.Done():
return ctx.Err()
case <-waitCh:
return nil
}
}txn.set(k,v []byte) 方法
set操作不会真正的写磁盘,只会对事务对象进行一定的操作,一切都基于内存,直到提交的时候才会持久化到磁盘,如果事务终止的话,直接将内存中的数据释放即可,也是保证事务一致性的因素之一
func (txn *Txn) Set(key, val []byte) error {
// 包装成entry
return txn.SetEntry(NewEntry(key, val))
}
func (txn *Txn) SetEntry(e *Entry) error {
return txn.modify(e)
}txn.modify(*Entry)方法
func (txn *Txn) modify(e *Entry) error {
// key的最大尺寸,因为key的最大长度的为uint32 65535
// 在写入key的时候,会拼接提交时间戳(事务版本号)
const maxKeySize = 65000
switch {
// 是否为只读事务
case !txn.update:
return ErrReadOnlyTxn
case txn.discarded:
// 事务是否已提交
return ErrDiscardedTxn
// 如果key为空
case len(e.Key) == 0:
return ErrEmptyKey
// 通过前缀判断是否为内部key (!badger!)
// 不得不吐槽一下,这个设计有点屎,干嘛不设计个CF呢
case bytes.HasPrefix(e.Key, badgerPrefix):
return ErrInvalidKey
// 检查key大小是否超出约定值
case len(e.Key) > maxKeySize:
// Key length can't be more than uint16, as determined by table::header. To
// keep things safe and allow badger move prefix and a timestamp suffix, let's
// cut it down to 65000, instead of using 65536.
return exceedsSize("Key", maxKeySize, e.Key)
// 判断vlog大小是否超出约定之
case int64(len(e.Value)) > txn.db.opt.ValueLogFileSize:
return exceedsSize("Value", txn.db.opt.ValueLogFileSize, e.Value)
case txn.db.opt.InMemory && int64(len(e.Value)) > txn.db.valueThreshold():
return exceedsSize("Value", txn.db.valueThreshold(), e.Value)
}
// 检查事务的尺寸
if err := txn.checkSize(e); err != nil {
return err
}
// The txn.conflictKeys is used for conflict detection. If conflict detection
// is disabled, we don't need to store key hashes in this map.
// 判断当前事务是否开启事务冲突检测
if txn.db.opt.DetectConflicts {
// 根据key的内存地址计算memHash (这里使用hash值来检测key的冲突,在一定程度上会有误判的情况)
fp := z.MemHash(e.Key) // Avoid dealing with byte arrays.
// 写到事务冲突的判断集合
txn.conflictKeys[fp] = struct{}{}
}
// If a duplicate entry was inserted in managed mode, move it to the duplicate writes slice.
// Add the entry to duplicateWrites only if both the entries have different versions. For
// same versions, we will overwrite the existing entry.
// 获取老的entry,判断是否成功和是否重复提交
if oldEntry, ok := txn.pendingWrites[string(e.Key)]; ok && oldEntry.version != e.version {
// 如果是重复写入(版本号相同的key在一个事务中set多次)
// 单独记录到duplicateWrites数组
txn.duplicateWrites = append(txn.duplicateWrites, oldEntry)
}
txn.pendingWrites[string(e.Key)] = e
return nil
}Txn 结构体
type Txn struct {
...
pendingWrites map[string]*Entry // cache stores any writes done by txn.
duplicateWrites []*Entry // Used in managed mode to store duplicate entries.
...
}txn.get(k []byte) 方法
func (txn *Txn) Get(key []byte) (item *Item, rerr error) {
// key为空直接返回错误
if len(key) == 0 {
return nil, ErrEmptyKey
// 如果事务已经结束则返回错误
} else if txn.discarded {
return nil, ErrDiscardedTxn
}
item = new(Item)
// 如果是读写事务
if txn.update {
// 判断当前key是否在之前被写入过,判断key是否相等,此方法实现了事务的隔离性
if e, has := txn.pendingWrites[string(key)]; has && bytes.Equal(key, e.Key) {
// 如果相同则直接组装数据并返回
// 判断是否被删除或过期
if isDeletedOrExpired(e.meta, e.ExpiresAt) {
return nil, ErrKeyNotFound
}
// Fulfill from cache.
item.meta = e.meta
item.val = e.Value
item.userMeta = e.UserMeta
item.key = key
item.status = prefetched
item.version = txn.readTs
item.expiresAt = e.ExpiresAt
// We probably don't need to set db on item here.
return item, nil
}
// Only track reads if this is update txn. No need to track read if txn serviced it
// internally.
// 标记当前key被读取,放入到一个read数组中,记录当前事务都读取了哪些key
txn.addReadKey(key)
}
// 从lsm-tree中真正的读取数据,之后再详细解读
seek := y.KeyWithTs(key, txn.readTs)
vs, err := txn.db.get(seek)
if err != nil {
return nil, y.Wrapf(err, "DB::Get key: %q", key)
}
if vs.Value == nil && vs.Meta == 0 {
return nil, ErrKeyNotFound
}
if isDeletedOrExpired(vs.Meta, vs.ExpiresAt) {
return nil, ErrKeyNotFound
}
item.key = key
item.version = vs.Version
item.meta = vs.Meta
item.userMeta = vs.UserMeta
item.vptr = y.SafeCopy(item.vptr, vs.Value)
item.txn = txn
item.expiresAt = vs.ExpiresAt
return item, nil
}txn.Commit() 方法
func (txn *Txn) Commit() error {
// txn.conflictKeys can be zero if conflict detection is turned off. So we
// should check txn.pendingWrites.
// 判断当前txn中是否有set操作发生过
if len(txn.pendingWrites) == 0 {
return nil // Nothing to do.
}
// Precheck before discarding txn.
// 进行相关的预处理检查
if err := txn.commitPrecheck(); err != nil {
return err
}
defer txn.Discard()
// 真正的提交到oracle,通知oracle,当前的事务对象已经提交,可以更新水位线
// 即比水位时间戳小的读取事务继续执行
txnCb, err := txn.commitAndSend()
if err != nil {
return err
}
// If batchSet failed, LSM would not have been updated. So, no need to rollback anything.
// 调用返回的闭包
return txnCb()
}txn.commitPrecheck() 方法
func (txn *Txn) commitPrecheck() error {
// 判断事务是否已提交
if txn.discarded {
return errors.New("Trying to commit a discarded txn")
}
keepTogether := true
// 遍历发生过修改的key,进行一些检查
for _, e := range txn.pendingWrites {
if e.version != 0 {
keepTogether = false
}
}
// If keepTogether is True, it implies transaction markers will be added.
// In that case, commitTs should not be never be zero. This might happen if
// someone uses txn.Commit instead of txn.CommitAt in managed mode. This
// should happen only in managed mode. In normal mode, keepTogether will
// always be true.
if keepTogether && txn.db.opt.managedTxns && txn.commitTs == 0 {
return errors.New("CommitTs cannot be zero. Please use commitAt instead")
}
return nil
}txn.commitAndSend() 方法
func (txn *Txn) commitAndSend() (func() error, error) {
orc := txn.db.orc
// Ensure that the order in which we get the commit timestamp is the same as
// the order in which we push these updates to the write channel. So, we
// acquire a writeChLock before getting a commit timestamp, and only release
// it after pushing the entries to it.
// 给oracle实例上写锁,以保证按事务提交的顺序写入到磁盘
orc.writeChLock.Lock()
defer orc.writeChLock.Unlock()
// 创建提交时间戳
commitTs, conflict := orc.newCommitTs(txn)
// 检查冲突情况
if conflict {
return nil, ErrConflict
}
keepTogether := true
// 设置版本号,把key后面拼接一个后缀(版本号)的闭包
setVersion := func(e *Entry) {
if e.version == 0 {
e.version = commitTs
} else {
keepTogether = false
}
}
// 遍历设置版本号
for _, e := range txn.pendingWrites {
setVersion(e)
}
// The duplicateWrites slice will be non-empty only if there are duplicate
// entries with different versions.
// 遍历设置版本号
for _, e := range txn.duplicateWrites {
setVersion(e)
}
// 把 pendingWrites 和 duplicateWrites 组装成一个entry数组
entries := make([]*Entry, 0, len(txn.pendingWrites)+len(txn.duplicateWrites)+1)
// 处理enry的闭包
processEntry := func(e *Entry) {
// Suffix the keys with commit ts, so the key versions are sorted in
// descending order of commit timestamp.
e.Key = y.KeyWithTs(e.Key, e.version)
// Add bitTxn only if these entries are part of a transaction. We
// support SetEntryAt(..) in managed mode which means a single
// transaction can have entries with different timestamps. If entries
// in a single transaction have different timestamps, we don't add the
// transaction markers.
if keepTogether {
e.meta |= bitTxn
}
entries = append(entries, e)
}
// The following debug information is what led to determining the cause of
// bank txn violation bug, and it took a whole bunch of effort to narrow it
// down to here. So, keep this around for at least a couple of months.
// var b strings.Builder
// fmt.Fprintf(&b, "Read: %d. Commit: %d. reads: %v. writes: %v. Keys: ",
// txn.readTs, commitTs, txn.reads, txn.conflictKeys)
// 遍历处理组装entry
for _, e := range txn.pendingWrites {
processEntry(e)
}
// 遍历处理组装entry
for _, e := range txn.duplicateWrites {
processEntry(e)
}
// 这里先不用管
if keepTogether {
// CommitTs should not be zero if we're inserting transaction markers.
y.AssertTrue(commitTs != 0)
e := &Entry{
Key: y.KeyWithTs(txnKey, commitTs),
Value: []byte(strconv.FormatUint(commitTs, 10)),
meta: bitFinTxn,
}
entries = append(entries, e)
}
// 把entry写请求打包好,批量发送给db实例进行异步写入
req, err := txn.db.sendToWriteCh(entries)
if err != nil {
orc.doneCommit(commitTs)
return nil, err
}
// 返回ret的闭包,再commit的最后执行
ret := func() error {
// 等待写操作完成
err := req.Wait()
// Wait before marking commitTs as done.
// We can't defer doneCommit above, because it is being called from a
// callback here.
// 标记commit操作完成
orc.doneCommit(commitTs)
return err
}
return ret, nil
}oracle.newCommitTs()方法
func (o *oracle) newCommitTs(txn *Txn) (uint64, bool) {
o.Lock()
defer o.Unlock()
// 检查活跃的事务是否冲突,已经提交的事务不需要检查
if o.hasConflict(txn) {
return 0, true
}
var ts uint64
if !o.isManaged {
// 对读取操作标记完成
o.doneRead(txn)
// 清理已完成事务
o.cleanupCommittedTransactions()
// This is the general case, when user doesn't specify the read and commit ts.
// 读取时间戳是next-1,提交时间戳是next
ts = o.nextTxnTs
o.nextTxnTs++
// 此时读取操作结束,进入事务提交阶段,不能再进行事务的其他操作(不需要上锁)
o.txnMark.Begin(ts)
} else {
// If commitTs is set, use it instead.
ts = txn.commitTs
}
y.AssertTrue(ts >= o.lastCleanupTs)
// 冲突检测
if o.detectConflicts {
// We should ensure that txns are not added to o.committedTxns slice when
// conflict detection is disabled otherwise this slice would keep growing.
// 读阶段完成,提交阶段没有完成的事务会记录到o.committedTxns
o.committedTxns = append(o.committedTxns, committedTxn{
ts: ts, // 提交版本号
conflictKeys: txn.conflictKeys, // 冲突检查的set(事务写的key)
})
}
return ts, false
}oracle.hasConflict() 方法
// hasConflict must be called while having a lock.
func (o *oracle) hasConflict(txn *Txn) bool {
// reads数组为0则无冲突
if len(txn.reads) == 0 {
return false
}
// commitedTxns: 表示活跃事务的数组
for _, committedTxn := range o.committedTxns {
// If the committedTxn.ts is less than txn.readTs that implies that the
// committedTxn finished before the current transaction started.
// We don't need to check for conflict in that case.
// This change assumes linearizability. Lack of linearizability could
// cause the read ts of a new txn to be lower than the commit ts of
// a txn before it (@mrjn).
// 判断事务时间戳是否小于读取时间戳
if committedTxn.ts <= txn.readTs {
// 如果小于,则不会影响的事务的读取
continue
}
// 遍历事务读取的key,如果在别的事务中发生过修改操作,如果是则发生冲突
for _, ro := range txn.reads {
if _, has := committedTxn.conflictKeys[ro]; has {
return true
}
}
}
return false
}oracle.doneRead() 方法
func (o *oracle) doneRead(txn *Txn) {
if !txn.doneRead {
txn.doneRead = true
// 通知readMark完成
o.readMark.Done(txn.readTs)
}
}
func (w *WaterMark) Done(index uint64) {
// 创建一个mark实例,向markchannel发送消息
w.markCh <- mark{index: index, done: true}
}oracle.cleanupCommittedTransactions() 方法
func (o *oracle) cleanupCommittedTransactions() { // Must be called under o.Lock
// 检查版本冲突
if !o.detectConflicts {
// When detectConflicts is set to false, we do not store any
// committedTxns and so there's nothing to clean up.
return
}
// Same logic as discardAtOrBelow but unlocked
var maxReadTs uint64
// 获取最大读取时间戳
if o.isManaged {
maxReadTs = o.discardTs
} else {
// 获取读事务标记水位作为最大读取时间戳
maxReadTs = o.readMark.DoneUntil()
}
// 断言是否大于最后清理时间戳
y.AssertTrue(maxReadTs >= o.lastCleanupTs)
// do not run clean up if the maxReadTs (read timestamp of the
// oldest transaction that is still in flight) has not increased
// 如果等于则直接返回
if maxReadTs == o.lastCleanupTs {
return
}
// 如果不等于,则赋值最后清理时间戳为最大读取时间戳
o.lastCleanupTs = maxReadTs
// 创建空切片
tmp := o.committedTxns[:0]
// 小于水位的事务已经不会产生冲突了,清理数组
for _, txn := range o.committedTxns {
if txn.ts <= maxReadTs {
continue
}
// 活跃状态的保存
tmp = append(tmp, txn)
}
o.committedTxns = tmp
}db.sendToWriteCh() 方法
异步写入
func (db *DB) sendToWriteCh(entries []*Entry) (*request, error) {
if atomic.LoadInt32(&db.blockWrites) == 1 {
return nil, ErrBlockedWrites
}
var count, size int64
// 遍历entrys,计算数据条数
for _, e := range entries {
size += e.estimateSizeAndSetThreshold(db.valueThreshold())
count++
}
// 现在单词事务最大写入
if count >= db.opt.maxBatchCount || size >= db.opt.maxBatchSize {
return nil, ErrTxnTooBig
}
// We can only service one request because we need each txn to be stored in a contigous section.
// Txns should not interleave among other txns or rewrites.
req := requestPool.Get().(*request)
req.reset()
req.Entries = entries
req.Wg.Add(1)
req.IncrRef() // for db write
// 打包好的整个事务请求,传到写事务channel,真正的写入到磁盘
db.writeCh <- req // Handled in doWrites.
y.NumPutsAdd(db.opt.MetricsEnabled, int64(len(entries)))
return req, nil
}watermark.process() 方法
process用于处理Mark通道。这不是线程安全的,因此只为进程运行一个 goroutine。一个就足够了,因为所有 goroutine 操作都使用纯粹的内存和 cpu。每个索引必须按顺序发出至少一个开始水位,否则等待者可能会无限期地被阻塞。
示例:我们在 100 处有一个水位,在 101 处有一个等待者,如果在索引 101 处没有发出水印,那么等待者将无限期地卡住,因为它无法决定 101 处的任务是否已决定不发出水位或它没有安排好了
整个方法使用cas和局部变量,最终保证了原子性
// process is used to process the Mark channel. This is not thread-safe,
// so only run one goroutine for process. One is sufficient, because
// all goroutine ops use purely memory and cpu.
// Each index has to emit atleast one begin watermark in serial order otherwise waiters
// can get blocked idefinitely. Example: We had an watermark at 100 and a waiter at 101,
// if no watermark is emitted at index 101 then waiter would get stuck indefinitely as it
// can't decide whether the task at 101 has decided not to emit watermark or it didn't get
// scheduled yet.
func (w *WaterMark) process(closer *z.Closer) {
defer closer.Done()
// 创建一个堆
var indices uint64Heap
// pending maps raft proposal index to the number of pending mutations for this proposal.
// 记录并发冲突值的用于检测的实例
pending := make(map[uint64]int)
// 存储回调channel, 一个时间戳上可以等待多个channel, 在orcale.readTs()中的waitForMark()
waiters := make(map[uint64][]chan struct{})
// 初始化堆
heap.Init(&indices)
// 真正执行逻辑的闭包函数
processOne := func(index uint64, done bool) {
// If not already done, then set. Otherwise, don't undo a done entry.
// 通过传入的时间戳,从pending数组中取值
prev, present := pending[index]
// 如果不存在则push进堆中
if !present {
heap.Push(&indices, index)
}
delta := 1
// 根据done判断是开始事务还是结束事务进行置位1或-1
if done {
delta = -1
}
// 如果是一个begin操作,即开启事务的标记的时候,在pending数组计数位里+1
// 如果是一个commit操作,即终止事务的标记的时候,在pending数组计数位里-1
// 让所有事务都能感知到活跃事务之间的关联
pending[index] = prev + delta
// Update mark by going through all indices in order; and checking if they have
// been done. Stop at the first index, which isn't done.
// 获取当前的水位信息
doneUntil := w.DoneUntil()
// 当前水位大于时间戳,证明已经不需要再去关注并发性了
if doneUntil > index {
// 断言结束操作
AssertTruef(false, "Name: %s doneUntil: %d. Index: %d", w.Name, doneUntil, index)
}
until := doneUntil
loops := 0
// 循环对堆数组进行pop遍历操作,弹出最小的事务的时间戳
for len(indices) > 0 {
min := indices[0]
// 判断是否大于0,证明最小的事务时间戳没有结束
if done := pending[min]; done > 0 {
// 没有其他事务在等待,跳出循环
break // len(indices) will be > 0.
}
// Even if done is called multiple times causing it to become
// negative, we should still pop the index.
// done <= 0 则说明事务已经提交,删除它曾经存在的痕迹
heap.Pop(&indices)
delete(pending, min)
// 水位移动
until = min
loops++
}
// 判断水位是否发生了变化
if until != doneUntil {
// 有所变化则通过cas赋值
AssertTrue(atomic.CompareAndSwapUint64(&w.doneUntil, doneUntil, until))
}
// 唤醒操作的闭包
notifyAndRemove := func(idx uint64, toNotify []chan struct{}) {
// 遍历通知channel的数组,一个个close掉
for _, ch := range toNotify {
close(ch)
}
// 在waiters中移除对应的时间戳
delete(waiters, idx) // Release the memory back.
}
// 如果水位发生移动
if until-doneUntil <= uint64(len(waiters)) {
// Issue #908 showed that if doneUntil is close to 2^60, while until is zero, this loop
// can hog up CPU just iterating over integers creating a busy-wait loop. So, only do
// this path if until - doneUntil is less than the number of waiters.
// 遍历原水位到当前水位
for idx := doneUntil + 1; idx <= until; idx++ {
// 把水位中的index拿出,得到回调函数的channel
if toNotify, ok := waiters[idx]; ok {
// 进行逐个关闭
notifyAndRemove(idx, toNotify)
}
}
} else {
for idx, toNotify := range waiters {
if idx <= until {
notifyAndRemove(idx, toNotify)
}
}
} // end of notifying waiters.
}
// 此方法的主体,循环for-select处理
for {
select {
// 关闭任务
case <-closer.HasBeenClosed():
return
// 接收markChannel, 100长的channel
case mark := <-w.markCh:
// 判断有无水位的信息
if mark.waiter != nil {
// 获取已提交事务的最大版本号的水位
doneUntil := atomic.LoadUint64(&w.doneUntil)
// 比较时间戳大小关系,如果当前已提交事务时间戳大于读时间戳,不需要等待,直接close
if doneUntil >= mark.index {
close(mark.waiter)
} else {
// 否则的话,读时间戳大于水位时间戳
// 在之前有未完成的活跃事务,不能获取读取时间戳,否则可能读取道脏数据
// 创建waiters
ws, ok := waiters[mark.index]
if !ok {
// 如果该读时间戳未在waiters中存在,创建channel数组
waiters[mark.index] = []chan struct{}{mark.waiter}
} else {
// 如果不空的话,说明之前已经有其他的事务在找个时间戳上等待,直接append
waiters[mark.index] = append(ws, mark.waiter)
}
}
// 读取时间戳和提交时间戳的操作都没有mark对象
} else {
// 如果当前时间戳是有效的
if mark.index > 0 {
// 对这个时间戳调用闭包进行逻辑处理
// mark.done是一个bool值,在begin的时候是false,在完成的时候为true
processOne(mark.index, mark.done)
}
// 遍历堆数组,对所有的节点进行一次处理逻辑
for _, index := range mark.indices {
processOne(index, mark.done)
}
}
}
}
}总结
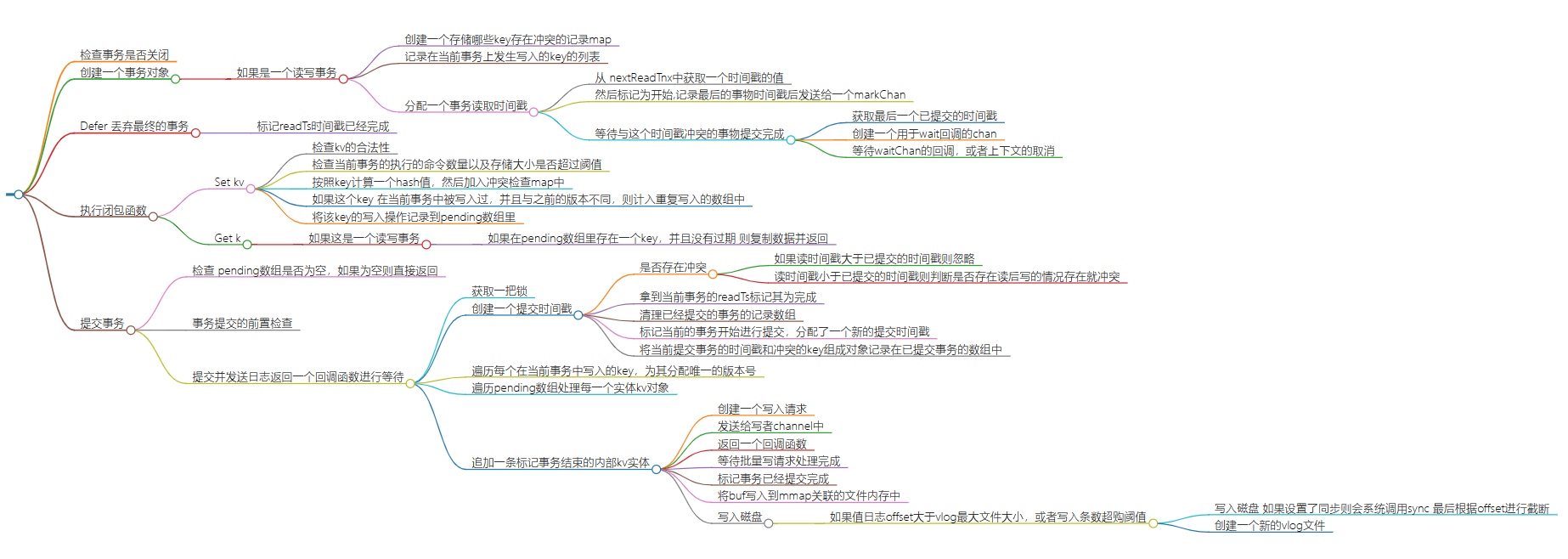
1. 检查事务是否关闭
2. 创建一个事务对象
1. 如果是一个读写事务
1. 创建一个存储哪些key存在冲突的记录map
2. 记录在当前事务上发生写入的key的列表
3. 分配一个事务读取时间戳
1. 从 nextReadTnx中获取一个时间戳的值
2. 然后标记为开始,记录最后的事物时间戳后发送给一个markChan
3. 等待与这个时间戳冲突的事物提交完成
1. 获取最后一个已提交的时间戳
2. 创建一个用于wait回调的chan
3. 等待waitChan的回调,或者上下文的取消
3. Defer 丢弃最终的事务
1. 标记readTs时间戳已经完成
4. 执行闭包函数
1. Set kv
1. 检查kv的合法性
2. 检查当前事务的执行的命令数量以及存储大小是否超过阈值
3. 按照key计算一个hash值,然后加入冲突检查map中
4. 如果这个key 在当前事务中被写入过,并且与之前的版本不同,则计入重复写入的数组中
5. 将该key的写入操作记录到pending数组里
2. Get k
1. 如果这是一个读写事务
1. 如果在pending数组里存在一个key,并且没有过期 则复制数据并返回
5. 提交事务
1. 检查 pending数组是否为空,如果为空则直接返回
2. 事务提交的前置检查
3. 提交并发送日志返回一个回调函数进行等待
1. 获取一把锁
2. 创建一个提交时间戳
1. 是否存在冲突
1. 如果读时间戳大于已提交的时间戳则忽略
2. 读时间戳小于已提交的时间戳则判断是否存在读后写的情况存在就冲突
2. 拿到当前事务的readTs标记其为完成
3. 清理已经提交的事务的记录数组
4. 标记当前的事务开始进行提交,分配了一个新的提交时间戳
5. 将当前提交事务的时间戳和冲突的key组成对象记录在已提交事务的数组中
3. 遍历每个在当前事务中写入的key,为其分配唯一的版本号
4. 遍历pending数组处理每一个实体kv对象
5. 追加一条标记事务结束的内部kv实体
1. 创建一个写入请求
2. 发送给写者channel中
3. 返回一个回调函数
1. 等待批量写请求处理完成
2. 标记事务已经提交完成
3. 将buf写入到mmap关联的文件内存中
4. 写入磁盘
1. 如果值日志offset大于vlog最大文件大小,或者写入条数超购阈值
1. 写入磁盘 如果设置了同步则会系统调用sync 最后根据offset进行截断
2. 创建一个新的vlog文件